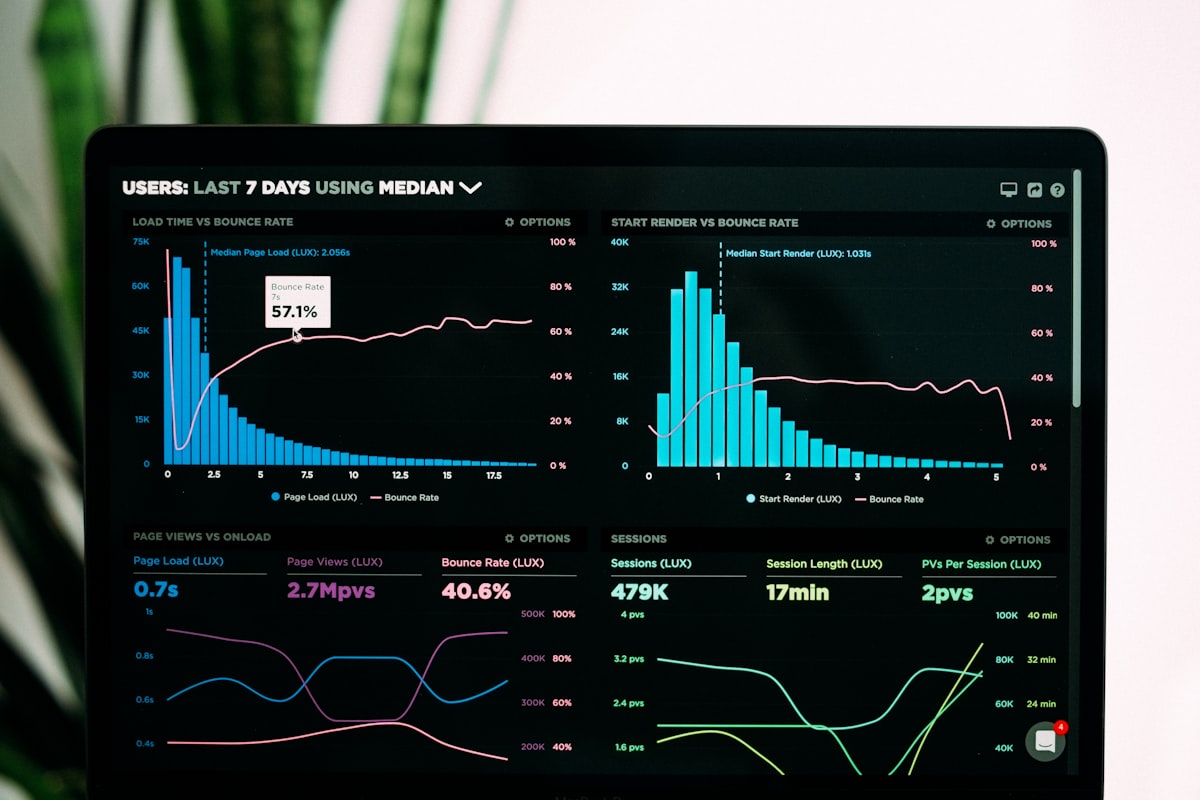
2026 OpenRouter Classement hebdomadaire des tokens : données de facturation, routing Agent & Mac distant
Du 18 au 24 mai 2026, la plateforme OpenRouter a traité 28,9 billions de tokens en une semaine — cinquième hausse consécutive. DeepSeek V4 Flash domine avec 3,43 billions, suivi de Tencent Hy3 Preview à 3,07 billions. Les modèles chinois totalisent 9,223 billions, devançant les modèles américains (4,93 billions) pour la quatrième semaine d'affilée. Ce guide propose une lecture professionnelle de ces chiffres — au-delà du bruit des benchmarks — et une feuille de route pour router vos agents OpenClaw sur un Mac distant Apple Silicon, stable et toujours disponible.
1. La facturation comme vérité du marché
Il existe une différence fondamentale entre ce qu'un modèle peut faire en laboratoire et ce que les équipes productives choisissent d'appeler chaque jour. OpenRouter agrège plus de 300 modèles derrière une API unifiée et traite environ 100 billions de tokens par mois. Son classement hebdomadaire ne classe pas les annonces marketing : il classe les tokens réellement consommés, payants ou gratuits.
Il y a un an, le volume hebdomadaire tournait autour de 2,4 billions. Aujourd'hui, 28,9 billions — soit un facteur douze en un an. Ce n'est pas une mode passagère : c'est la signature d'une industrie qui déplace ses chatbots expérimentaux vers des pipelines d'agents permanents, des revues de code automatisées et des inférences batch dans les départements IT.
Les benchmarks académiques — SWE-bench, MMLU, HumanEval — restent précieux pour fixer un plafond de qualité. Mais ils ne répondent pas à la question que se pose un directeur technique un lundi matin : « Quel modèle absorbera mon volume sans faire exploser la facture ? » Les données de facturation OpenRouter apportent cette réponse avec une élégance statistique : chaque euro ou dollar dépensé est un vote.
Pour les studios créatifs, agences et équipes produit qui déploient déjà OpenClaw ou des agents similaires, cette perspective change la donne. On ne choisit plus un LLM comme on choisissait un plugin Photoshop — par réputation. On le choisit comme on choisit un fournisseur cloud : par coût unitaire, latence sous charge, fiabilité des appels d'outils et adéquation au workflow.
Le rapport conjoint OpenRouter et a16z sur l'usage de l'IA en 2025 souligne une relation souvent inverse entre scores de benchmark et parts de marché. Les modèles les plus cités dans la presse tech ne sont pas toujours les plus sollicités dans les logs de production. Comprendre cette asymétrie, c'est déjà prendre une longueur d'avance sur les équipes qui alignent tout sur le modèle « numéro un du benchmark du trimestre ».
2. Source des données et périmètre statistique
Les chiffres cités proviennent du classement public accessible sur openrouter.ai/rankings. OpenRouter consolide les appels API de l'ensemble de sa base utilisateurs et distingue les modèles gratuits des modèles facturés. Pour chaque semaine, la plateforme publie le volume par modèle, les parts par pays d'origine de l'éditeur, et la césure entre part de tokens et part de revenus en dollars.
Date de référence pour cet article : 24 mai 2026. Les classements évoluent en continu ; nous recommandons une consultation hebdomadaire pour les décisions opérationnelles. Les taux de croissance mentionnés comparent la semaine du 18–24 mai à la semaine précédente — ils indiquent une tendance, pas une garantie pour un éditeur donné.
Trois réserves s'imposent à l'interprétation. D'abord, les modèles gratuits comme Owl Alpha gonflent parfois le volume avec des prototypes et des usages hobby — peu représentatif de l'entreprise. Ensuite, les clients disposant de contrats directs avec Anthropic ou Google n'apparaissent pas intégralement dans les statistiques OpenRouter. Enfin, la tokenisation varie selon les modèles : comparez preferentiellement au sein d'une même plateforme.
Malgré ces limites, aucune source publique n'offre une transparence comparable sur les parts de marché API. C'est la photographie la plus honnête de ce que le marché utilise réellement — et non ce qu'il déclare utiliser dans ses communiqués.
3. Panorama global : 28,9 billions et géopolitique des modèles
| Indicateur | Valeur | Évolution hebdo |
|---|---|---|
| Volume mondial hebdomadaire | 28,9 billions de tokens | +7,4 % (cinquième hausse consécutive) |
| Modèles chinois | 9,223 billions | +19,89 % |
| Modèles américains | 4,93 billions | +16,27 % |
| Chine vs États-Unis | La Chine mène pour la 4e semaine | Part passée de moins de 2 % début 2025 à plus de 45 % |
Le dépassement chinois n'est pas un accident statistique. Depuis le début de 2025, la part des modèles open source chinois sur OpenRouter progresse sans discontinuité — de moins de 2 % à plus de 45 % en mai 2026. Les développeurs votent avec leurs clés API : les architectures MoE de DeepSeek, Tencent, MiniMax et StepFun offrent, pour les workflows d'agents, un rapport qualité-prix difficile à ignorer.
Pour une agence parisienne ou un studio de post-production lyonnais, la question n'est pas abstraite. Intégrer des modèles chinois peut réduire drastiquement les coûts d'inférence — mais impose une analyse de conformité (RGPD, localisation des données) que les modèles américains ou européens self-hostés ne posent pas de la même manière. Le classement montre où va le marché ; votre matrice de conformité fixe où vous pouvez aller.
Notons que les deux blocs croissent vite : Chine +19,89 %, États-Unis +16,27 % semaine sur semaine. Le gâteau grossit plus vite que les parts ne se redistribuent — signe d'une adoption généralisée des agents, bien au-delà des early adopters de Silicon Valley.
4. Podium de la semaine et constellation DeepSeek
| Rang | Modèle | Éditeur | Tokens hebdo | Profil |
|---|---|---|---|---|
| 1 | DeepSeek-V4-Flash | DeepSeek (Chine) | 3,43T (+66 %) | Référence agents, prix minimal |
| 2 | Tencent Hy3 Preview | Tencent (Chine) | 3,07T (+16 %) | Croissance post-période gratuite |
| 3 | Claude Sonnet 4.6 | Anthropic (États-Unis) | 1,35T | Contexte million, code entreprise |
| 4 | DeepSeek-V3.2 | DeepSeek (Chine) | 1,31T | Longue traîne, usages créatifs |
| 5 | Owl Alpha | OpenRouter | 1,15T (+29 %) | Gratuit, spécialisé agents |
| 6–10 | Gemini 3 Flash / V4-Pro / MiniMax M2.7 / Grok 4.1 Fast / Step 3.5 Flash | Google / DeepSeek / MiniMax / xAI / StepFun | 673B–1,06T | Multimodal, flagship, long contexte, droit, batch |
DeepSeek place trois variantes dans le top neuf, pour un total d'environ 5,74 billions (+25,9 %). Un seul éditeur structure ainsi la couche agent de toute une plateforme. Kimi K2.6, présent les semaines précédentes, sort du top dix — rappel salutaire : un classement hebdomadaire n'est pas un contrat permanent.
Hy3 Preview mérite une attention particulière. Malgré la fin de sa phase gratuite, le volume progresse de 16 %. Cela suggère une adoption réelle en production, pas seulement un effet promotionnel. Pour les équipes déjà ancrées dans l'écosystème Tencent, Hy3 est un candidat naturel pour des tests en déploiement gris.
Claude Sonnet 4.6, troisième, confirme que les modèles enterprise américains conservent leur place sur les chemins de code exigeants — même si leur part globale de tokens recule. L'art du routing consiste à superposer les strates : volume économique en bas, qualité premium en escalade.
5. Trois écueils fréquents dans le choix d'un modèle
- Confondre benchmark et budget : un score SWE-bench élevé ne justifie pas de router chaque appel d'outil via Claude Opus. On optimise alors pour la vitrine, pas pour le retour sur investissement.
- Traiter les modèles gratuits comme de la production : Owl Alpha et autres modèles « stealth » peuvent journaliser les prompts. Code source avec secrets, données clients ou documents internes ne devraient pas transiter par des routes gratuites sans accord de traitement documenté.
- Oublier l'infrastructure : OpenClaw sur un portable en veille ne tient aucun canal — aussi brillant soit le routing défini sur papier. Modèle et gateway forment un seul système.
Ces erreurs, nous les observons dans des revues d'architecture aussi bien chez des startups que dans des groupes établis. Elles disparaissent lorsque classement hebdomadaire, conformité et stabilité du gateway sont examinés ensemble — chaque lundi, dans le même document.
6. Volume de tokens et revenus : deux tableaux, une stratégie
| Strate | Exemple | Profil tokens | Profil revenus |
|---|---|---|---|
| Haute valeur, faible volume | Claude Opus | environ 12 % des tokens (25 % il y a un an) | environ 46 % des revenus |
| Équilibre prix-volume | Gemini Flash | Stable en multimodal et recherche | Fourchette tarifaire médiane |
| Prix minimal, volume massif | DeepSeek / MiniMax / StepFun | Agents, code, batch | Beaucoup de tokens, peu de dollars |
Anthropic incarne le paradoxe de la prime : Claude Opus génère environ 25 millions de dollars de revenus mensuels avec un volume de tokens inférieur de plusieurs ordres de grandeur à DeepSeek. Le classement ne mesure pas l'intelligence — il mesure la fréquence d'appel sous contraintes de prix. Pour un CFO comme pour un lead tech, la couche revenus compte autant que la couche tokens.
Conséquence pratique : construisez votre table de routing OpenClaw en deux dimensions. Colonne coût pour le volume agent ; colonne réserve qualité pour Opus ou Sonnet en escalade. Une seule colonne mène soit à l'explosion budgétaire, soit à des goulots qualitatifs.
7. La programmation, moteur de plus de la moitié des usages
Le rapport d'usage OpenRouter/a16z documente un basculement structurel : la part des tâches liées à la programmation est passée d'environ 11 % à plus de 50 % de l'ensemble des workloads. Cela explique le duo DeepSeek V4 Flash / Claude Sonnet 4.6 en tête — deux réponses au même besoin (coder), à des points différents de la courbe coût-qualité.
Pour les équipes DevOps et platform, la leçon est claire : séparez explicitement vos scénarios de code — complétion inline, revue de PR, boucles agent avec tool-calling, refactoring batch. Chaque strate a des exigences de latence et de coût distinctes. Le classement hebdomadaire indique la direction du marché ; votre réglage fin reste par pipeline.
La programmation domine non parce que les autres usages disparaissent, mais parce que les frameworks d'agents — OpenClaw, Cursor Agent, étapes LLM en CI — tournent en parallèle massif et consomment des millions de tokens par tâche. Ignorer cette dynamique, c'est sous-estimer la facture avant même d'avoir livré la première feature.
8. Routing OpenClaw en cinq étapes
- Suivre le classement chaque semaine : ouvrir
openrouter.ai/rankings, consigner le Top 10 et les parts éditeurs. Marquer les nouveaux entrants — Hy3, Owl Alpha — souvent signe avant-coureur du prochain shift de volume. - Stratifier par tâche : agents batch et boucles tool-calling via DeepSeek V4 Flash ; inférence complexe et code sensible via Claude Opus ou Sonnet ; multimodal et documents via Gemini Flash.
- Écrire openclaw.json : modèles primaire et secours ; clés API exclusivement via SecretRef. Identifiants OpenRouter avec préfixe éditeur (
deepseek/,anthropic/,google/). - Gateway permanent sur Mac distant :
openclaw gateway installavec launchd. Synchroniser les espaces de travail via SFTP ou rsync pour conserver le contexte agent entre redémarrages. - Déploiement gris et repli : libérer les canaux production uniquement après
channels status --proberéussi. Bascule automatique sur le modèle secours en cas de HTTP 429 ou incident fournisseur.
openclaw doctor
openclaw channels status --probeCes cinq étapes forment un rituel opérationnel reproductible. Elles lient l'observation du marché à la configuration technique — et empêchent les décisions de modèle dans le vide.
9. Matrice de décision Mac distant 7×24
| Emplacement | Adapté à | Risque principal |
|---|---|---|
| Portable local | Lecture du classement, sessions de debug solo | Veille interrompt le gateway ; pas de couche agent 7×24 |
| VPS Linux minimal | Relais API pur sans toolchain Apple | Pas de Xcode, pas de notarisation ; pipeline macOS séparé |
| Mac distant SFTPMAC | Production OpenClaw + artefacts de build sur une machine | Planifier les droits répertoires (voir guides SFTP du blog) |
La matrice le rappelle avec élégance : choisir un modèle et choisir une infrastructure sont une seule décision. Ajuster le routing chaque semaine sur un portable endormi, c'est peaufiner la mauvaise variable. Un Mac distant Apple Silicon offre la persistance launchd, la toolchain native et la synchronisation SFTP/rsync — la combinaison qui transforme les chiffres du classement en ROI agent réel.
Pour les créatifs et développeurs qui travaillent déjà dans l'écosystème Apple — Final Cut, Xcode, workflows de design — un Mac distant n'est pas un compromis : c'est le prolongement naturel d'un environnement où les agents doivent cohabiter avec les outils de production, sans friction de plateforme.
10. Questions fréquentes
Différence avec notre article Top 10 de juin ? Celui-ci cible la semaine du 18–24 mai et l'angle « la facturation ne ment pas ». L'article de juin développe les tendances structurelles sur plusieurs semaines.
DeepSeek restera-t-il en tête ? La baisse permanente de V4-Pro à un quart du prix initial devrait consolider la domination. Le suivi hebdomadaire reste néanmoins indispensable.
Hy3 et DeepSeek pour des données personnelles ? Cela dépend de votre accord de traitement et de la catégorisation des données. Techniquement adaptés au volume agent ; juridiquement, une validation séparée s'impose.
11. Conclusion : lire la facture, déployer sur un nœud toujours éveillé
Le classement de la semaine du 18–24 mai 2026 dessine un marché où l'open source chinois redéfinit les coûts via le MoE ; où agents et programmation occupent le centre du plateau ; où Anthropic capitalise une prime là où la qualité est non négociable. Comprendre cette stratification, c'est dépasser la lecture naïve des benchmarks.
La limite n'est pas le modèle — c'est l'exploitation. Un gateway sur portable ou un VPS intermittent ne soutient pas un rituel hebdomadaire de routing. Les agents OpenClaw de longue durée exigent un nœud macOS accessible 7×24 avec des répertoires de travail synchronisés.
SFTPMAC Mac distant propose un hébergement Apple Silicon avec persistance launchd et intégration SFTP/rsync — pour que votre choix de modèle, guidé par le classement hebdomadaire, se traduise en pipelines agents productifs, et non en slides d'architecture jamais déployées.